«
Il y a trois types de mensonges : les mensonges, les sacrés mensonges et les statistiques ». Cette phrase de Benjamin Disraeli trouve son origine dans un usage inadapté des outils statistiques, dans le but de cautionner une intuition ou une conviction. Bien que décriée, cette pratique a malheureusement son pendant en recherche : le
p-value hacking, qui consiste à triturer les données jusqu’à obtenir la significativité désirée pour une hypothèse testée, au détriment de certaines règles statistiques qui s’en trouvent violées. Le plus souvent, cela est fait en toute bonne foi puisque l’objectif est de tirer le meilleur parti possible des données tout en se conformant aux exigences de publication. Malgré tout, il est indispensable de limiter cette pratique qui engendre de nombreuses fausses découvertes.
Cela est d’autant plus vraie en protéomique, en raison de la complexité intrinsèque du protéome, mais aussi de l’évolution rapide des technologies analytiques. C’est notamment pour cela que de nombreux outils bioinformatiques et biostatistiques fleurissent régulièrement dans la littérature
[1], avec la promesse de pouvoir dépasser la triple limite des big proteomics data : leur grande taille, leur grande dimensionnalité, et leur grande complexité. Cependant, la simplicité qu’offrent ses outils ne saurait masquer la nécessité d’un minimum de compréhension théorique pour une utilisation et des résultats corrects.
C’est avec cet objectif que nous avons réalisé ces dernières années un effort particulier dans la divulgation de bonnes pratiques en science des données pour la protéomique
[2-4]. Nous avons ainsi publié une introduction à la théorie du FDR (
False Discovery rate, une mesure de contrôle qualité omniprésente), nous avons désambiguïsé un ensemble de termes ayant des significations différentes en intelligence artificielle et en chimie analytique, et avons également proposé cinq étapes de contrôle permettant d’améliorer la qualité d’une analyse protéomique différentielle entre plusieurs échantillons.
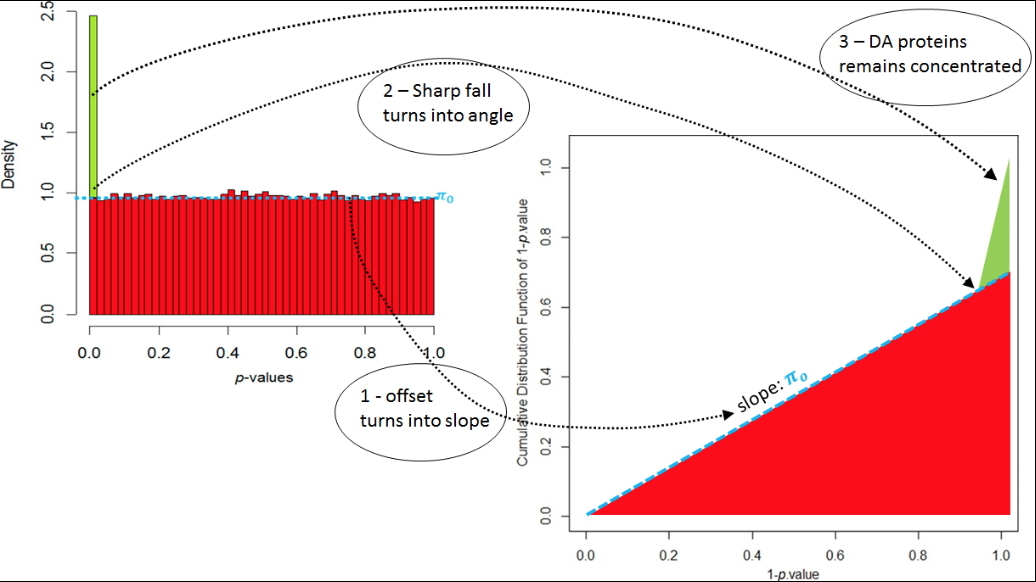
Construction graphique permettant d’estimer visuellement la qualité de la calibration des p-values.